

Зачем нужна информация об истории сайта в прошлом
Историю любого сайта можно посмотреть в интернете. Для этого достаточно, чтобы ресурс существовал хотя бы пару дней. Это может понадобиться в следующих случаях:
- Если необходимо купить домен, который уже был в использовании, и нужно посмотреть контент какой тематики был на нем размещен, не было ли огромного количества рекламы, исходящих ссылок и т.д.
- Нужен уникальный контент. Его можно скачать с существовавших когда-то ресурсов. Такое наполнение подойдет, например, для сайта-сателлита.
- Нужно восстановить сайт, когда нет его бэкапа.
- Нужно проанализировать конкурентов. Этот способ понадобится чтобы посмотреть историю изменений на их сайтах, какие ошибки они допускали или, наоборот, какие “фишки” стоит позаимствовать.
- Необходимо посмотреть страницу, если она теперь недоступна напрямую.
- Интересно , как выглядел ресурс 10-20 лет назад.
Ниже приведен пример того, как выглядела стартовая страница поисковой системы Яндекс в 2000 году:
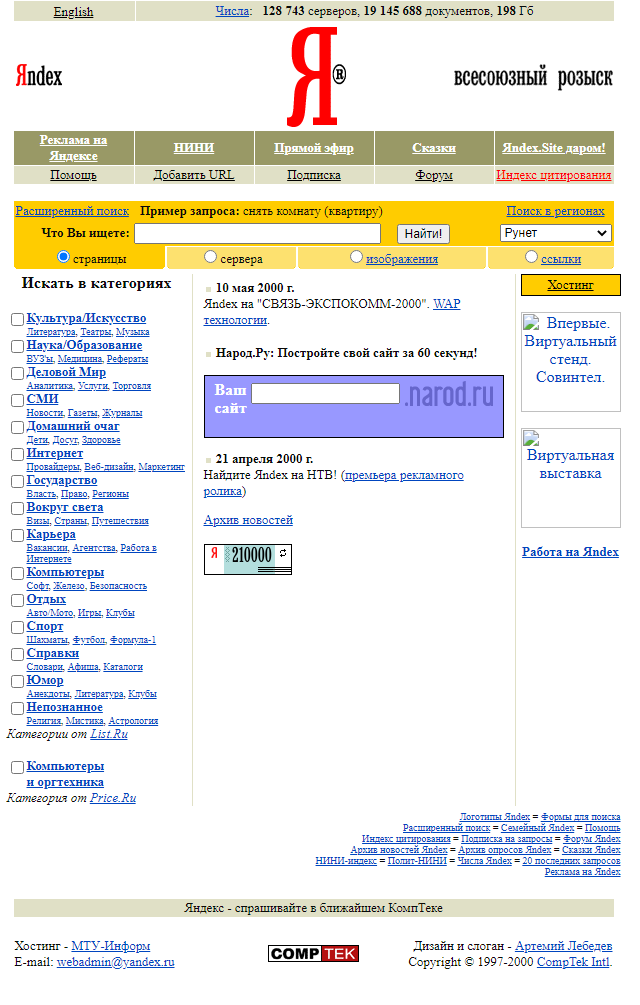
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
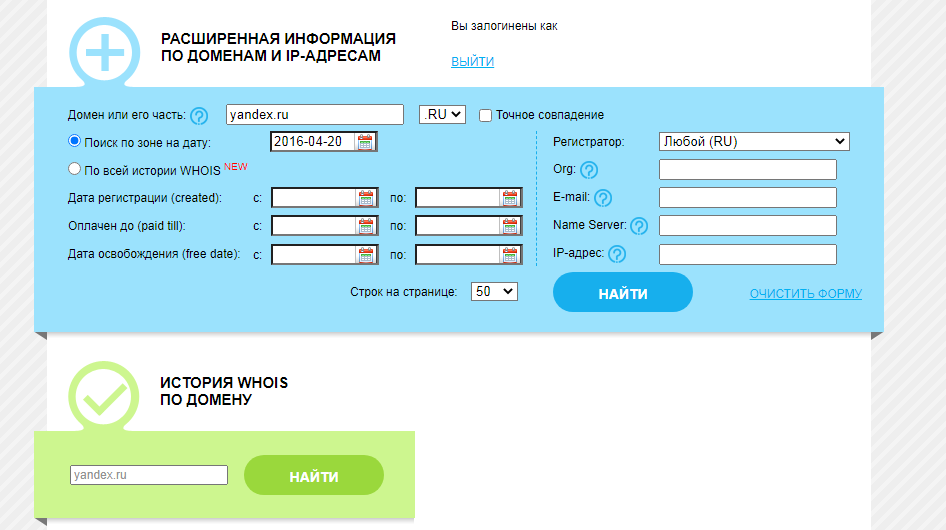
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:
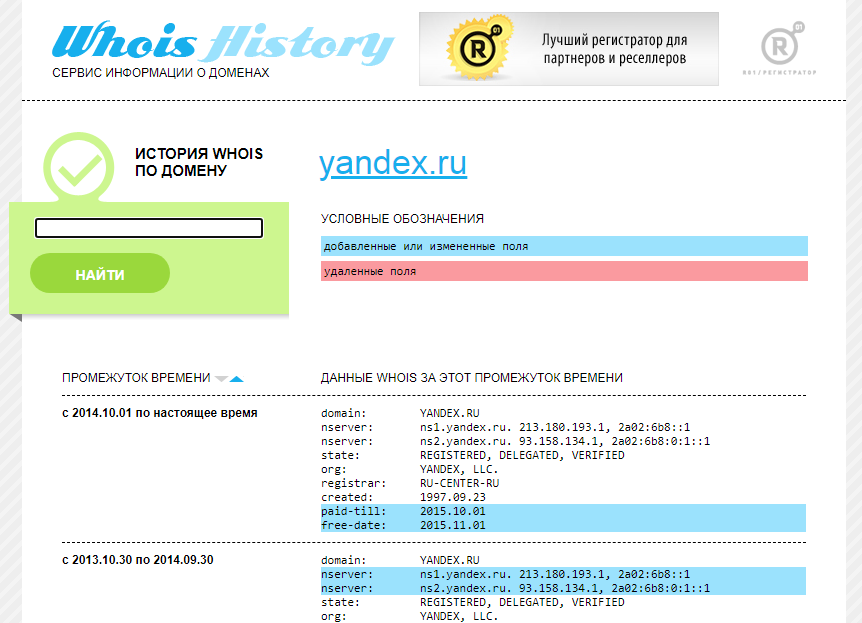
Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.
Сохраненная копия страницы в поисковых системах Яндекс и Google
Для сохранения копий страниц понадобятся дополнительные сервисы. Поисковые системы сохраняют последние версии страниц, которые были проиндексированы поисковым роботом.
Для этого в строке поиска Яндекс вводим адрес сайта с оператором site: или url: в зависимости от того, что хотим проверить конкретную страницу или ресурс целиком. Нажимаем на стрелочку рядом с URL и выбираем «Сохраненная копия».
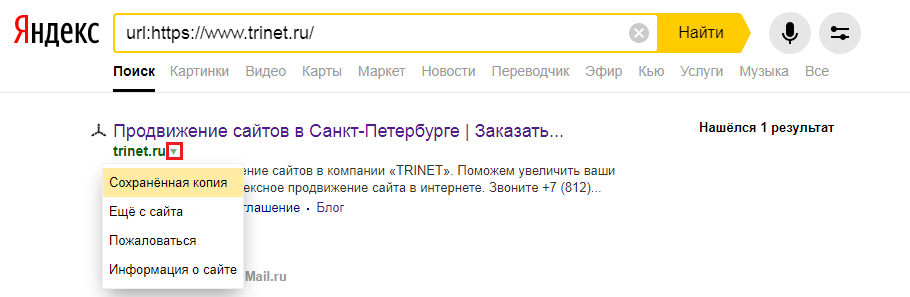
Откроется последняя версия страницы, которая есть у ПС. Можно посмотреть только текст, выбрав одноименную вкладку.

Посмотреть сохраненную копию конкретной страницы в Google можно с помощью оператора cache. Например, вводим cache:trinet.ru и получаем:

Вы так же можете посмотреть текстовую версию страницы.
Найти сохраненную версию страницы можно и через выдачу Google. Необходимо:
- использовать оператор site:, либо указать сразу необходимый URL
- найти страницу в выдаче
- нажать на стрелочку рядом с URL
- выбрать «Сохраненная копия»
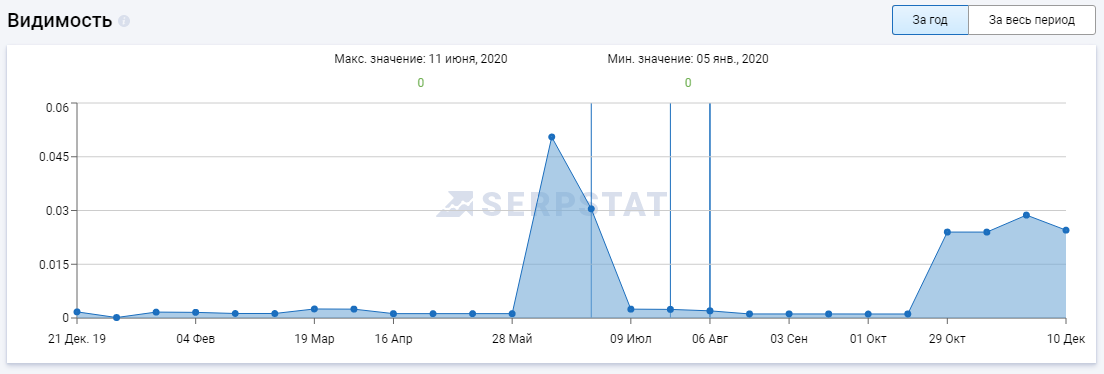
Платформа Serpstat
С помощью этого инструмента можно посмотреть изменения видимости сайта в поисковой выдаче за год или за все время, что сайт находится в базе Serpstat.
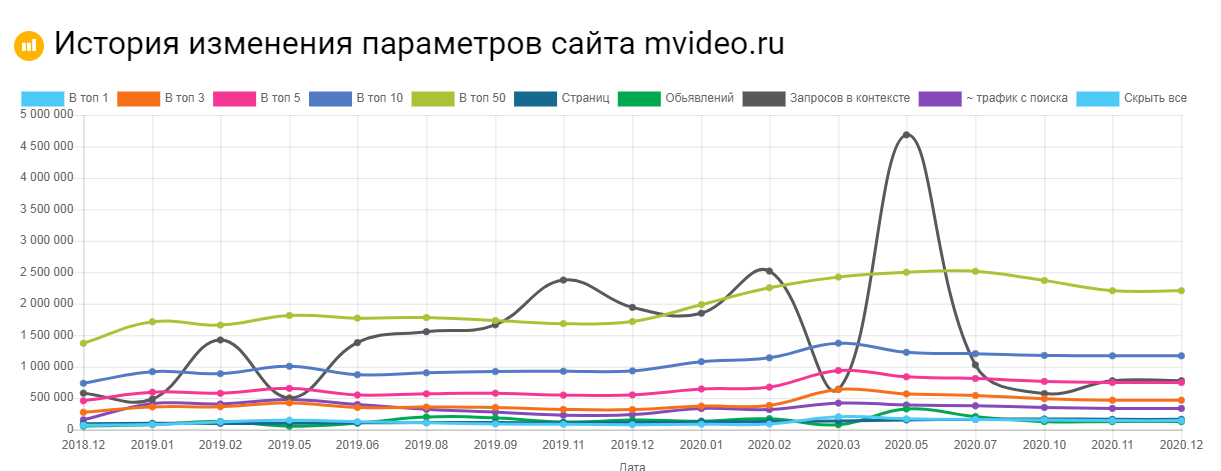
Сервис Keys.so
Используя этот сервис можно посмотреть, сколько страниц находится в выдаче, в ТОП – 1, ТОП – 3 и т.д. Можно регулировать параметры на графике и выгружать полную статистику в Excel.
Как восстановить сайт из архива
Часто нужно не только посмотреть, как менялись страницы в прошлом, но и скачать содержимое сайта. Это легко сделать с помощью автоматических сервисов.
О самых популярных расскажем ниже.
Сервис Архиварикс
Сервис может восстановить как рабочие, так и не рабочие сайты. Недоступные ресурсы он скачивает из Веб-архива. Для этого нужно заполнить данные на странице https://archivarix.com/ru/restore/ и нажать кнопку «Восстановить».
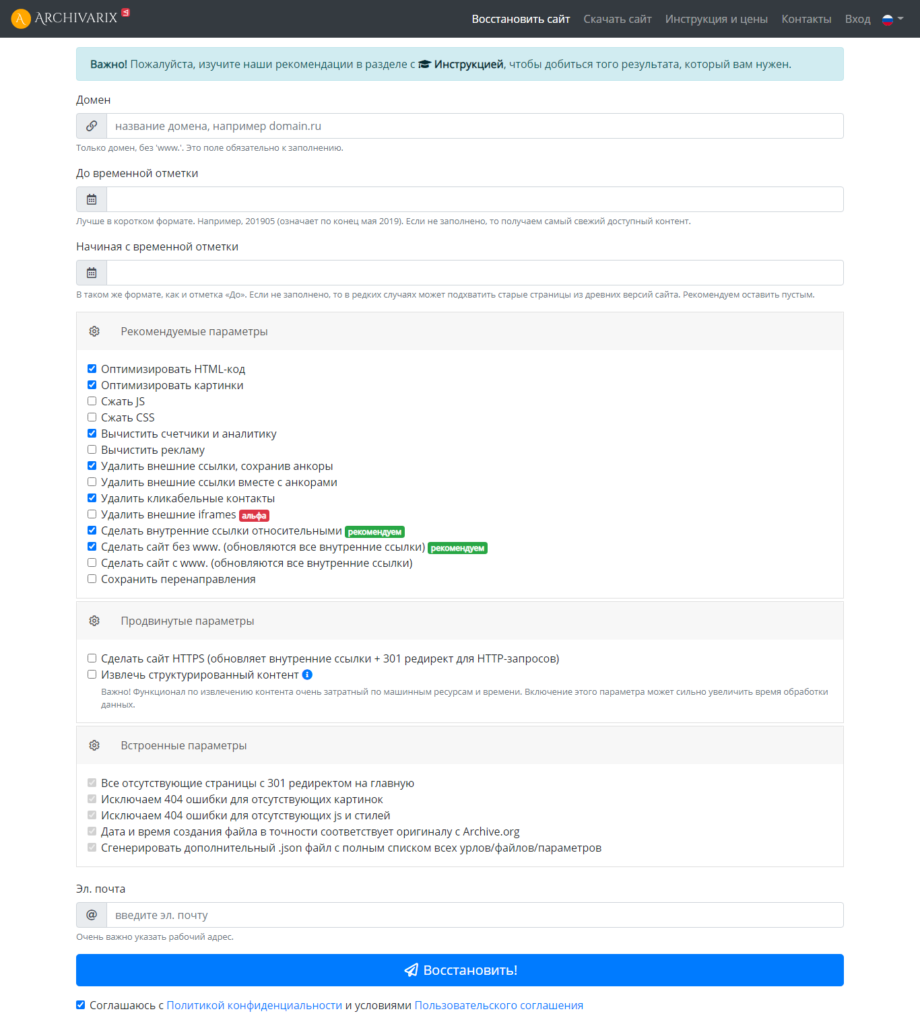
Для работы с полученными файлами Архиварикс предоставляет собственную систему CMS, которая совместима с любыми другими системами.
Сервис Rush Analytics
Данный сервис также восстанавливает сайты из Веб-архива. Можно задать нужную дату скачивания для любой страницы. На выходе получаем html-документ со всеми стилями, картинками и т.д.
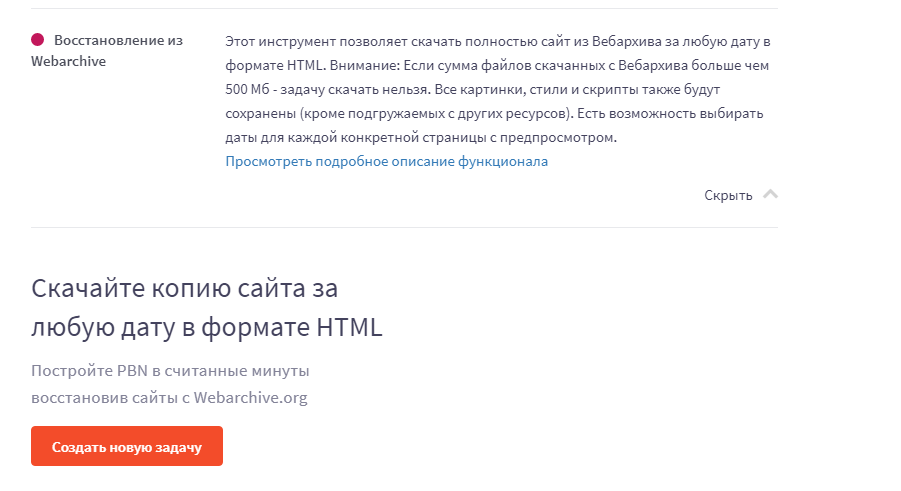
Ссылка на сервис https://www.rush-analytics.ru/land/skachivanie-kopiy-saytov-iz-wayback-machine
Сервис R-tools.org
Еще один сервис, который позволяет скачивать сайты из Веб-архива. Можно скачать сайт целиком, можно отдельные страницы. Оплата происходит только за то, что скачено, поэтому выгоднее использовать данный сервис только для небольших сайтов.
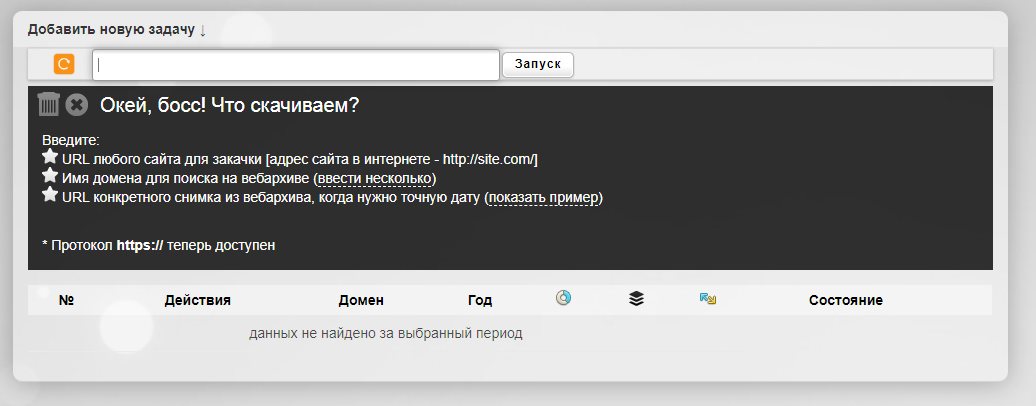
Сервис Wayback Machine Download (waybackmachinedownloader.com)
С помощью него можно скачивать данные из Веб-архива. Есть демо-версия. Подходит для больших проектов. Единственный минус – сервис не русифицирован.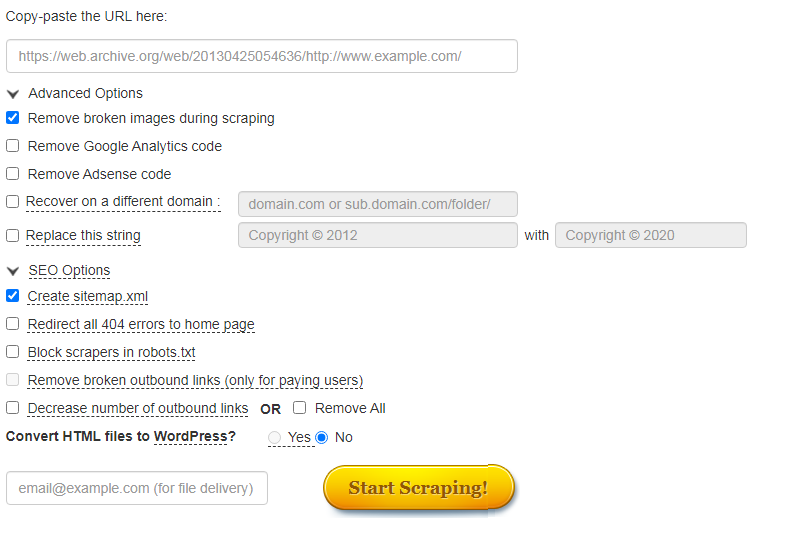
Сервис Mydrop.io
Этот сервис помогает найти уже освободившиеся или скоро освобождающиеся интересные домены по вашим параметрам.
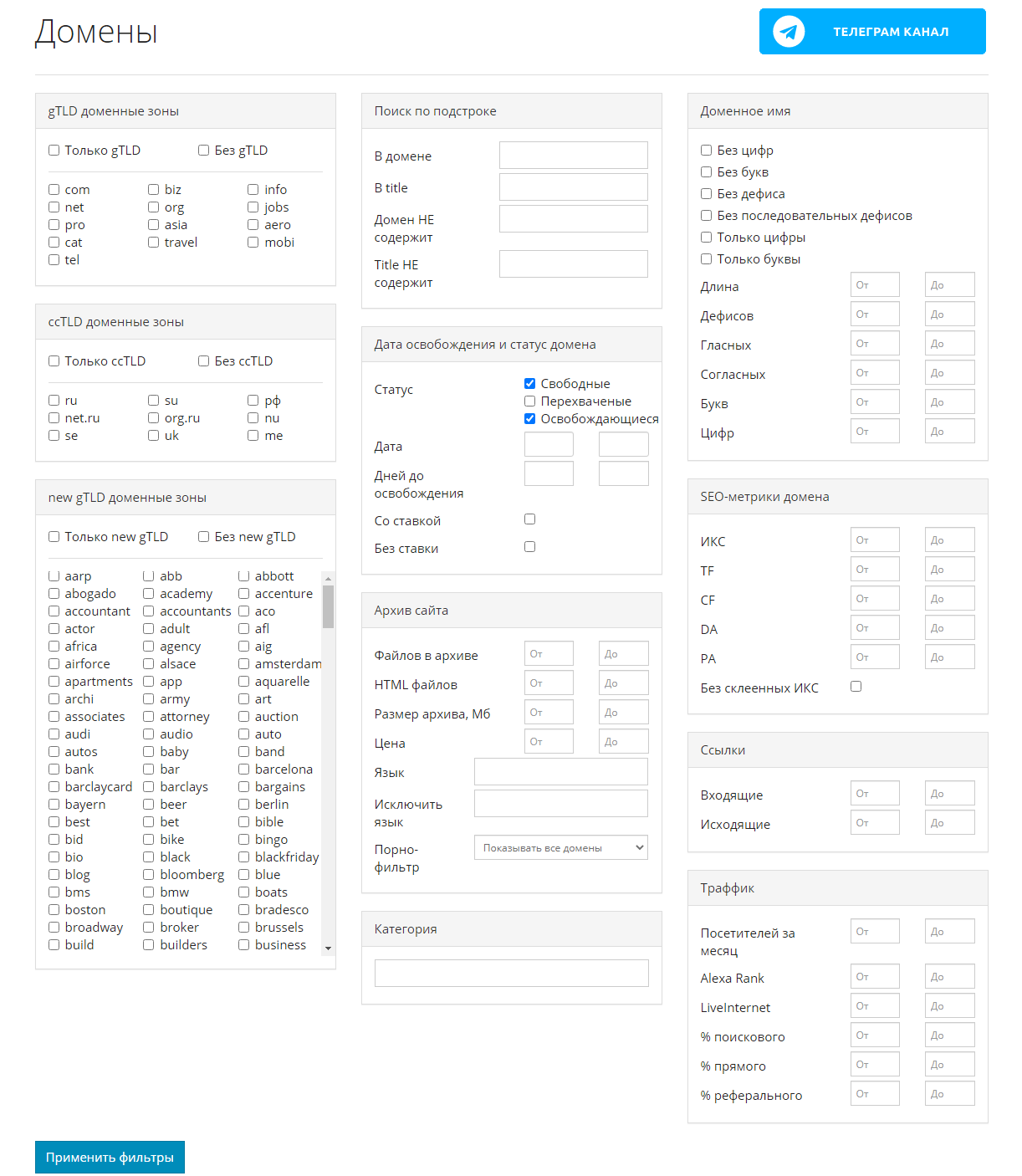
Для этого необходимо применить заданные фильтры, после чего можно скачать контент этих сайтов. Сервис делает скриншоты сайтов до их удаления. Перед скачиванием можно предварительно посмотреть содержимое ресурса. Особенностью является то, что данные выгружаются не из ВебАрхива, а из собственной базы.
Плагины
Восстановить сайт из бэкапа можно автоматически с помощью плагинов для CMS. Таких инструментов множество. Например, плагины Duplicator, UpdraftPlus для системы WordPress. Все, что нужно – это иметь резервную копию, которую также можно сделать с помощью этих плагинов, если сайтом владеете вы.
Множество сервисов, предоставляющие хостинг для сайта, сохраняют бэкапы и можно восстановить предыдущую версию собственного проекта.
Заключение
Мы привели примеры основных сервисов, в которых можно посмотреть изменения сайтов и восстановить их содержимое. Список не ограничивается только этими инструментами.
Если у вас есть интересные и проверенные сервисы, о которых мы не упомянули, расскажите в комментариях. А если нужна помощь со скачиванием контента или комплексные услуги по продвижению и созданию сайтов, обращайтесь к нашим специалистам.
И до встречи в следующей публикации!
Материал проверен редактором
Head of SEO в интернет-агентстве TRINET.Group
в SEO более 11 лет,
автор книги «Светлая сторона продвижения сайтов»,
организатор конференции SeoClubSpb.
30.12.2020

")
")
")